
Setup AI Code Completions In VS Code Using Ollama
Content
Background
There was a time when developers use to search for issues in Stack Overflow or learn how to write code for something from official documentation sites. People still do but I see many of us have started to rely on AI GPTs like ChatGPT, Perplexity AI, Google Gemini and more. Before all this LLMs came along, there was another super helpful tool introduced called Github Copilot. It was made available as Extension in VS Code and it seemed crazy how it automatically generated code, correct few mistakes and suggests code completion on the fly. A need to lookup things on browser started diminishing.
How about interacting with ChatGPT like LLMs offline and get code completions in code editor without paying a dime, everything living in your machine? There are number of advantages to this:
- It is FREE, without ADs & Open Source!
- It works offline without internet connection that means all data lives in your system.
- If you work at a strict business having stringent data compliances, something like offline LLM could save your day!
Prerequisites
To setup Ollama & a LLM model you need good internet connection. It may require 6 to 8 GB of data, so make sure you are connected to a high speed network. I am assuming you already have VS Code installed on your system.
You do not need to know anything about AI, Ollama, LLMs or similar buzzwords. It might be good to read & learn about them though!
While I will demonstrate the process below using Mac OS, but similar steps should work out for Windows or Linux.
Installing Ollama
The way I see Ollama, it is just a software that is designed to run a server to enable you to chat with AI model. It also helps you manage multiple AI models. It exposes API endpoints that one can utilise and build AI Chatbots or AI Agents leveraging it.
Download Ollama installer from ollama.com/download after choosing your OS. For macOS it will download zip, just extract and move it to Applications, like how we do for most applications. For windows it might open a regular installer, just follow the usual steps and you are good to go.
Launch Ollama application from spotlight (macOS) or start menu (windows), you should see welcome screen like below:
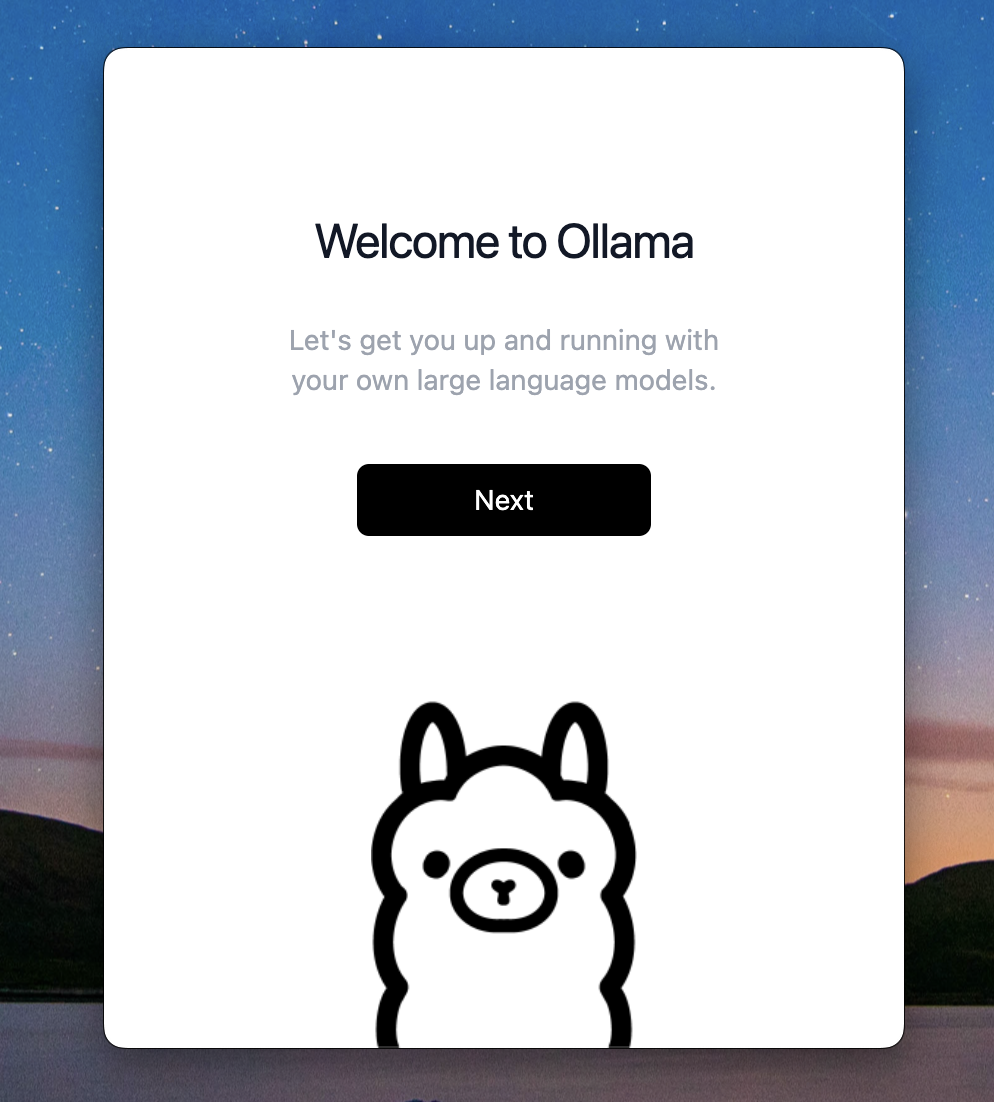
Click Next, it will ask you to install the command line, Click Install
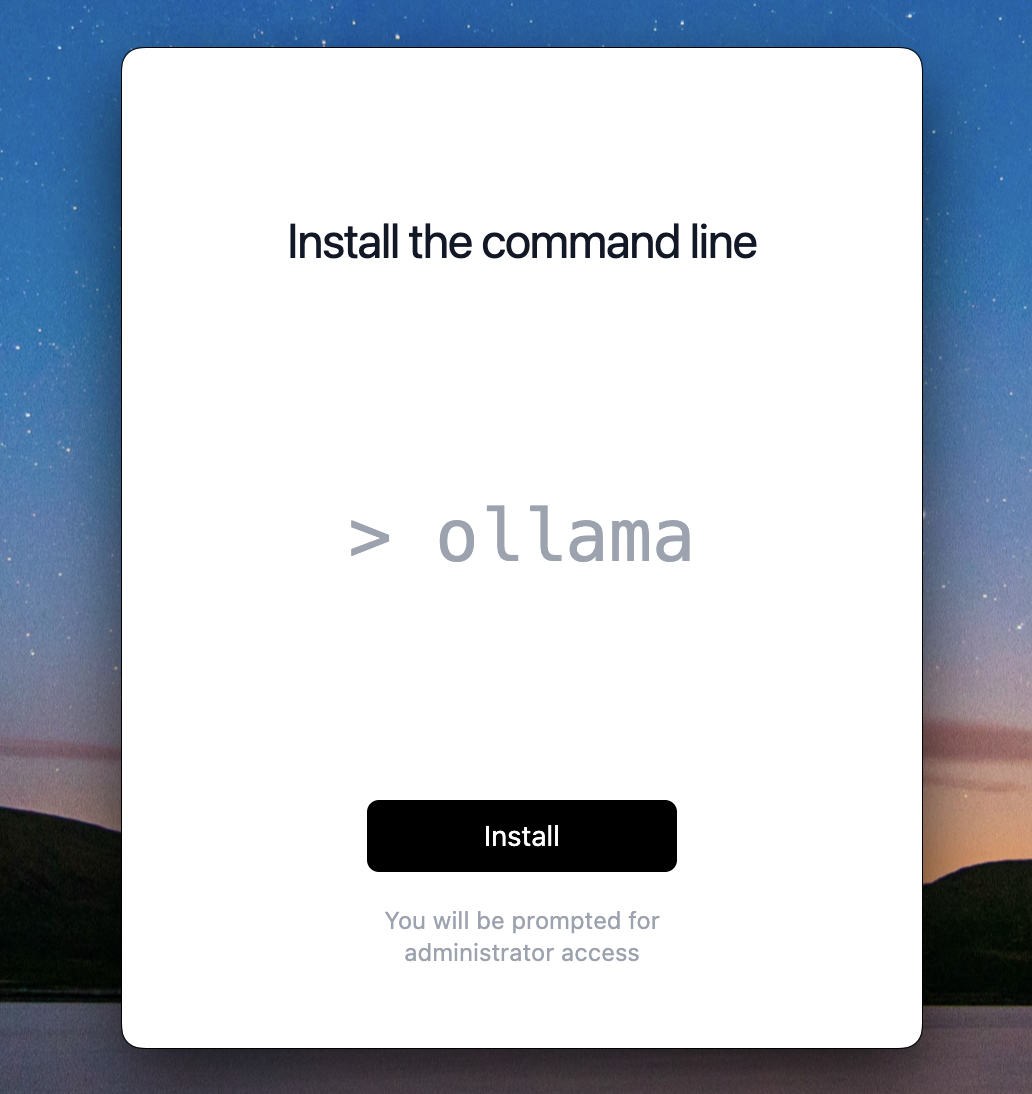
All done! it will finally show you command to run a model (which is not yet downloaded), we will talk about this in next section.
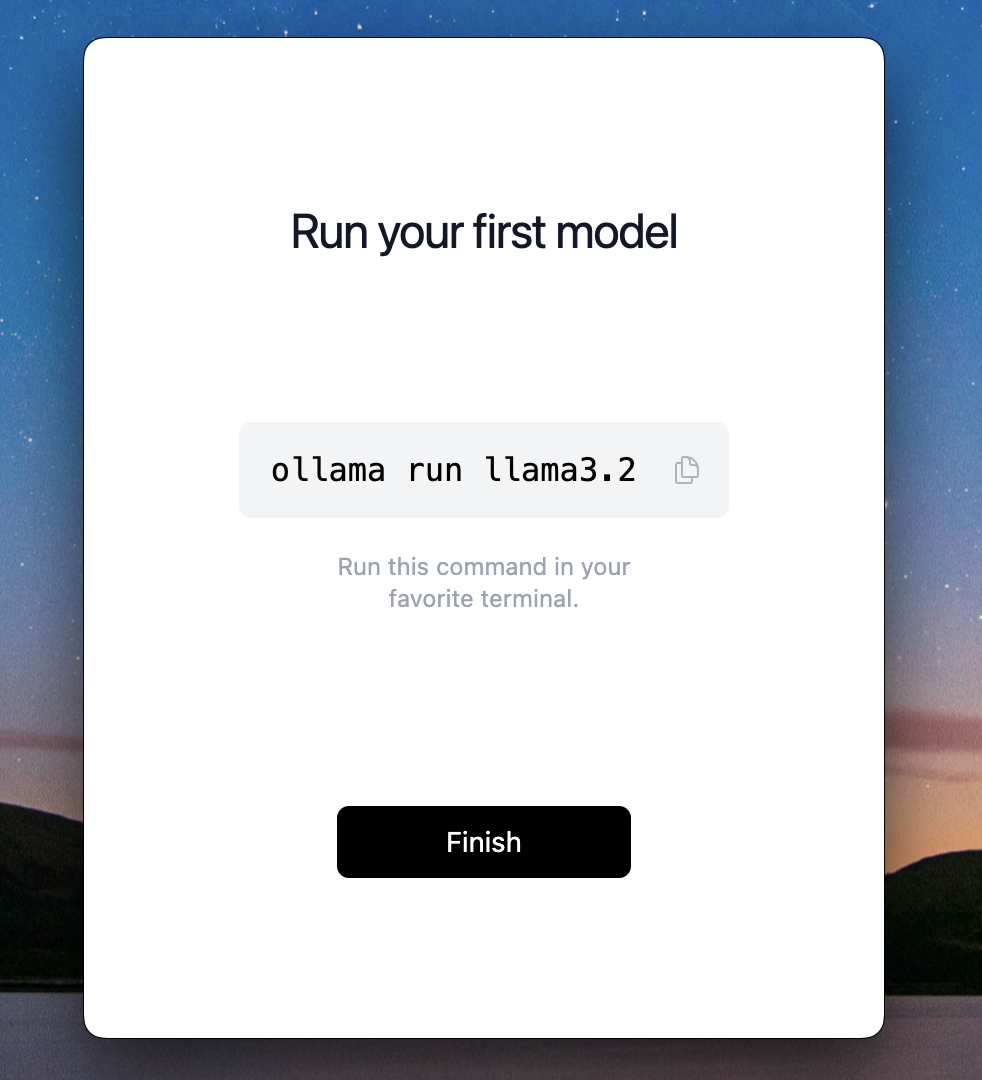
You can click Finish and Ollama popup will close, it will be running in background. In mac you will see Ollama icon at top right in menu bar. If you click on it, you will just see option to quit, don't click it yet & keep Ollama running.
Large Language Models (LLMs)
We know that a computer cpu processes information in bits of 0s and 1s. But it is difficult for us humans to write instructions in 0s and 1s. So we made Assembler that takes in Assembly language code and convert it into 0s and 1s. Then came programming languages which are kind of close to our daily speaking languages. And now, we have LLMs that can understand our language and can speak maybe better than us.
The idea is to have a computer understand instructions / tasks in the simplest way possible. With each era passing in computer science, we are closing-in in achieving this very goal. Therefore it was kind of a revolutionary moment when OpenAI made their ChatGPTs publicly accessible which can interpret our language and converse back with probable solutions, codes, diagrams, pictures (dall E), and much more. As of February 2025, one can just talk with ChatGPT like how we talk with anyone over phone!!
So LLMs are basically machine learning models trained on very huge, thousands or millions of gigabytes worth of textual information. That is why they are referred as "Large" Language Models. Because these models have gone through such vast examples of text, they can relate to many of those examples and respond us back with relevant information when we ask something. I suggest you to read more about it in this cloudflare blog post.
Let us get one LLM on your computer. Open Terminal / Command Prompt & type following (if terminal was already open, I suggest to restart it so that ollama commands are sourced.)
ollama help
This will list all available commands we can run. Notice a command called pull let us use that command to get a LLM good at coding. I prefer qwen2.5-coder model as you can see its evaluation result is quite impressive compared to others:
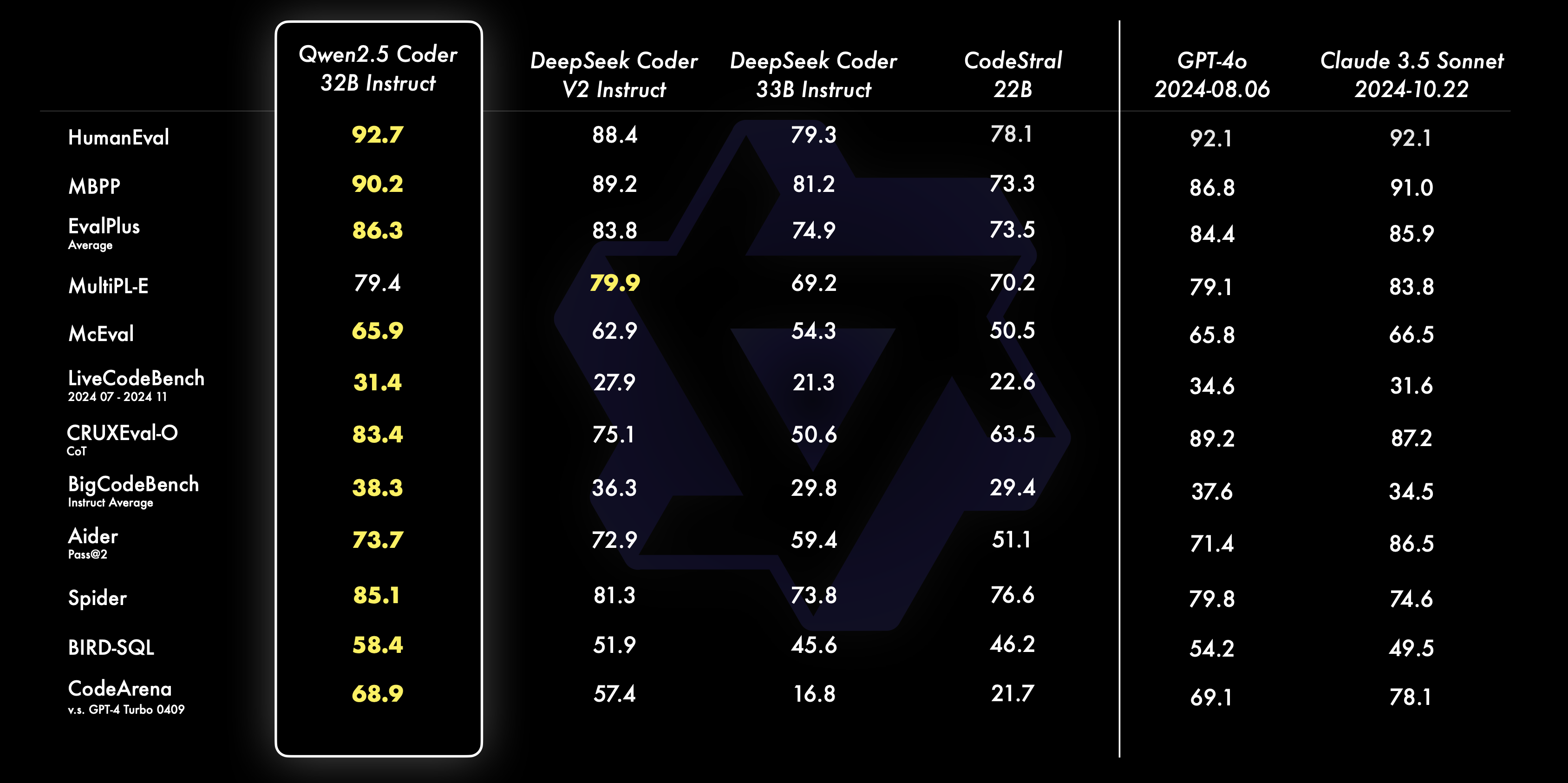
LLM models specifies parameters count like 7b, 14b, 32b.. b stands for billion. Ollama github repository has this note "You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models."I have considered Qwen2.5 Coder with 7B parameters to be suitable for my case. To get the model, run below command:
ollama pull qwen2.5-coder:7bYou can see list of all available parameters for Qwen2.5 Coder here. Once the pull is complete you can start running model with below command:
ollama run qwen2.5-coder:7b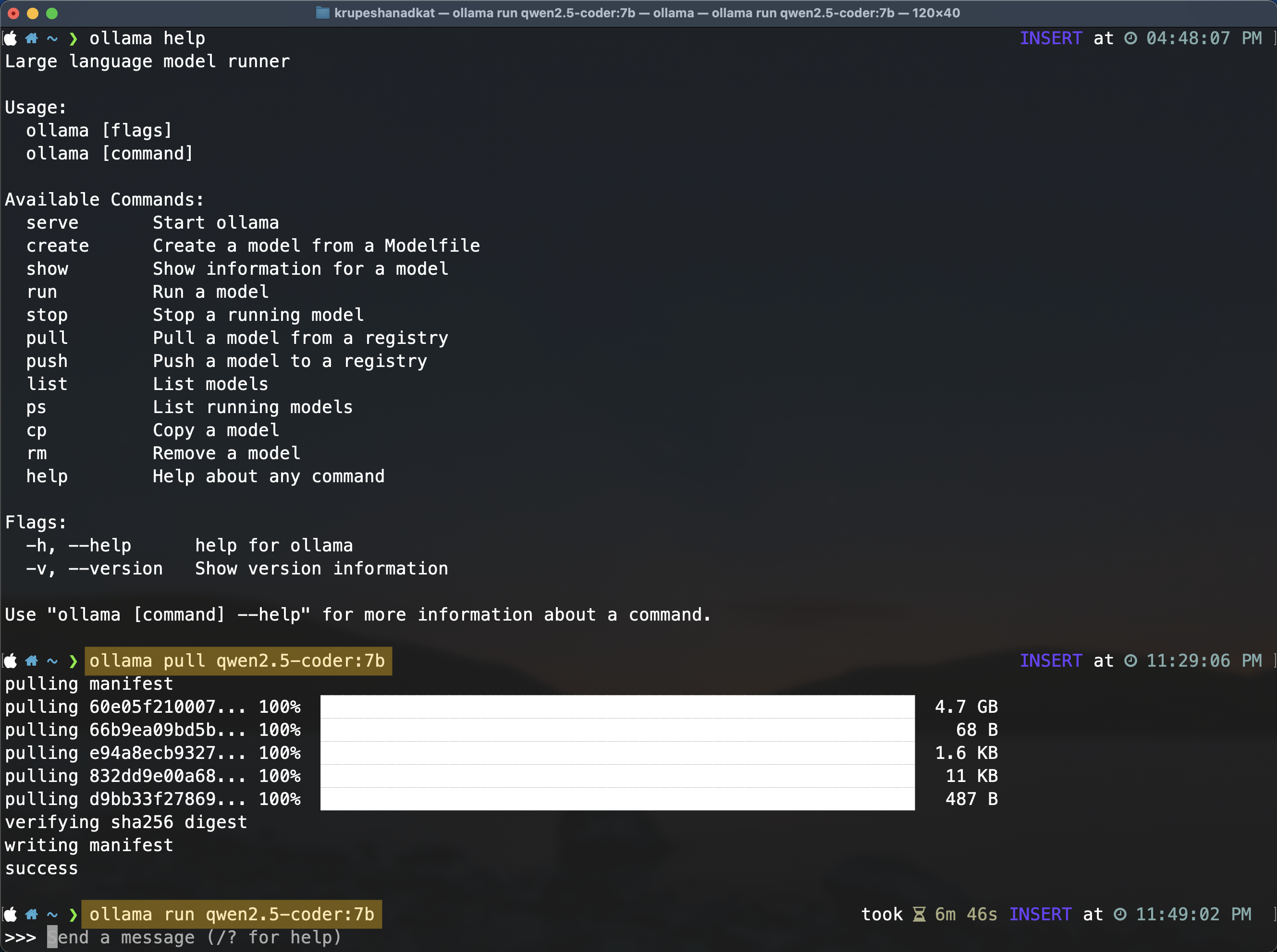
As soon as you type above run command, a prompt field appears. You can chat with your LLM model now. You can even turn off wifi of your laptop and try chatting offline.
Enter /bye to exit this prompt. To verify that ollama is serving this model in background, you can run this command:
ollama ps
This will list all running models.
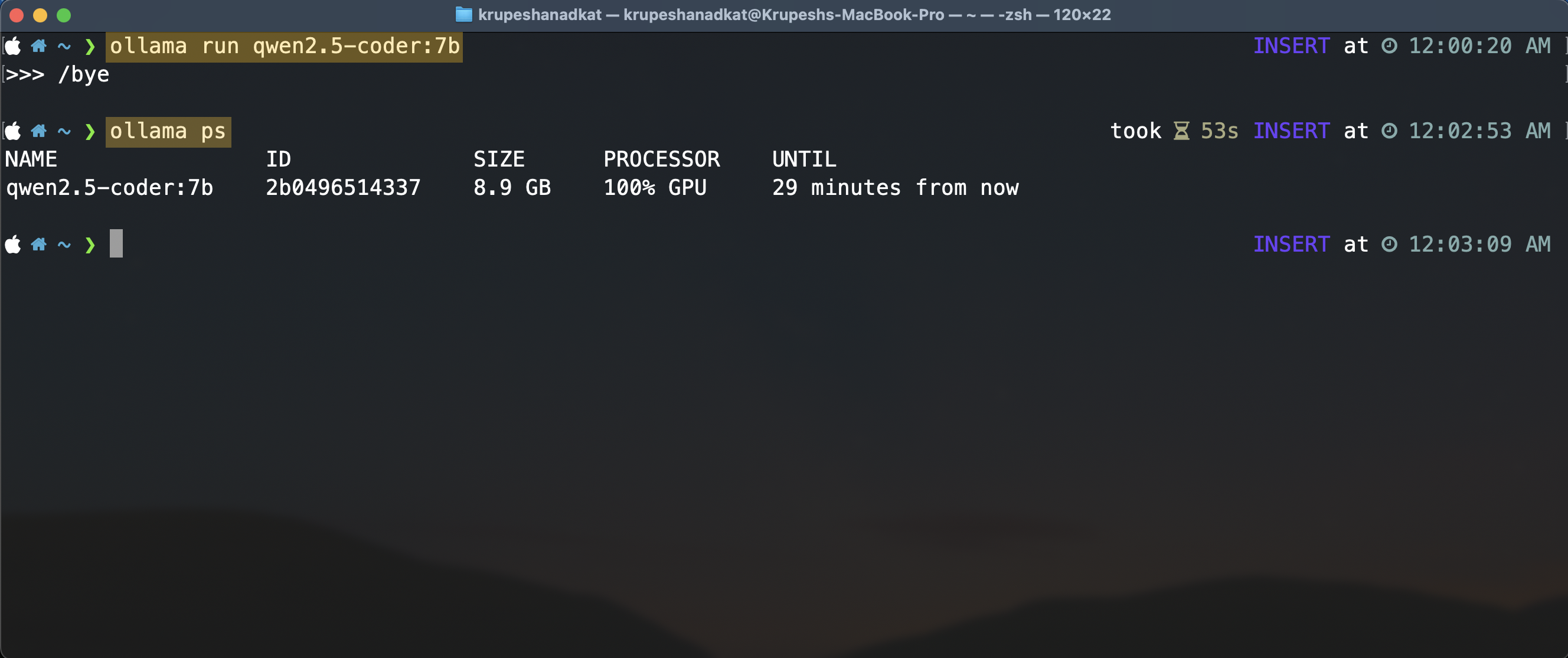
If you don't see model in the list, then just run it again and exit it with /bye again. Like how I have done in above screenshot. It is important to keep your model running in background else VS Code extension won't be able to utilise it.
VS Code & LLM Integration
This is the last part to achieve AI code completions in VS Code. Open Extensions view in VS Code
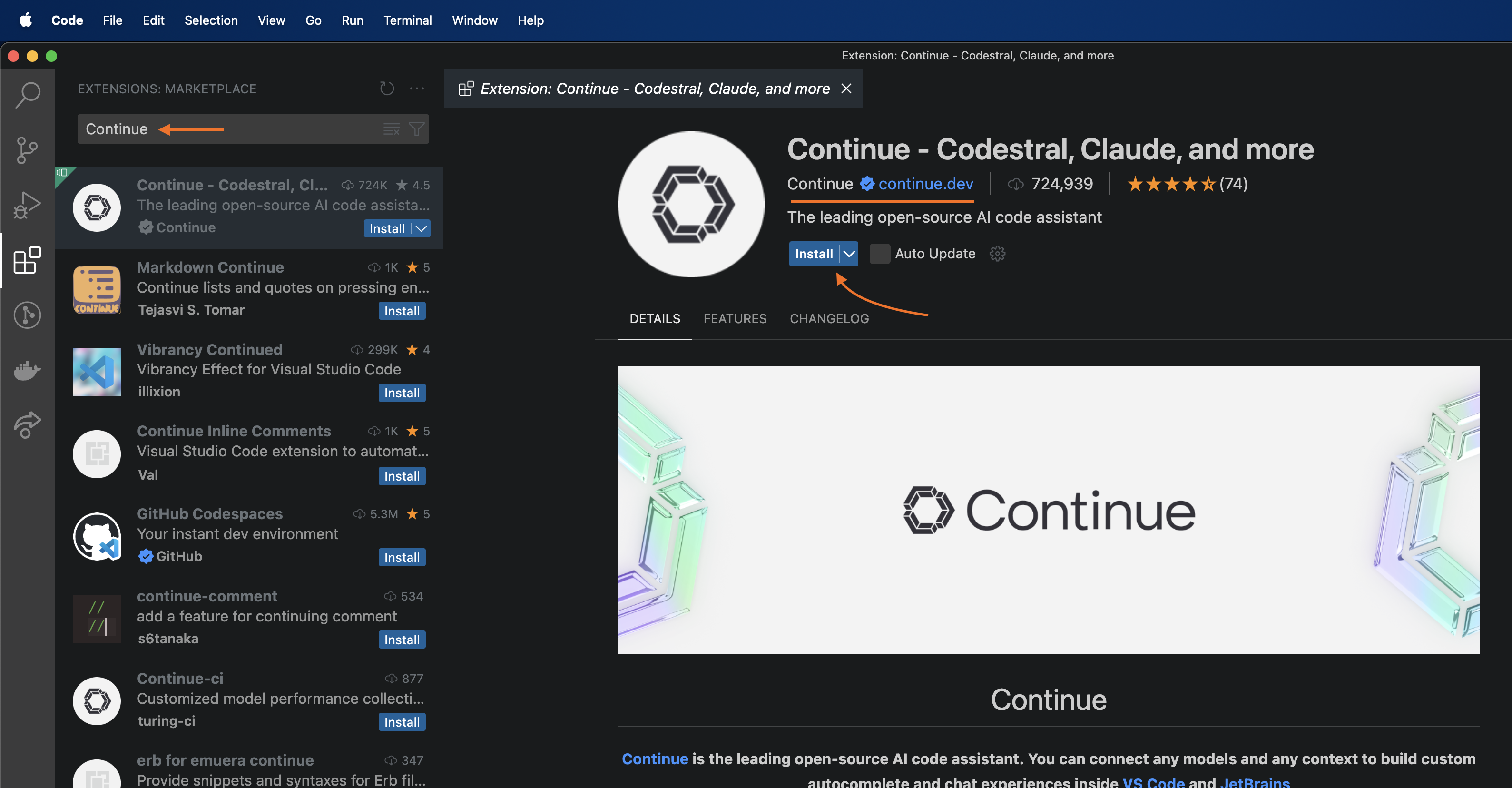
Search for Continue extension by continue.dev & click install.
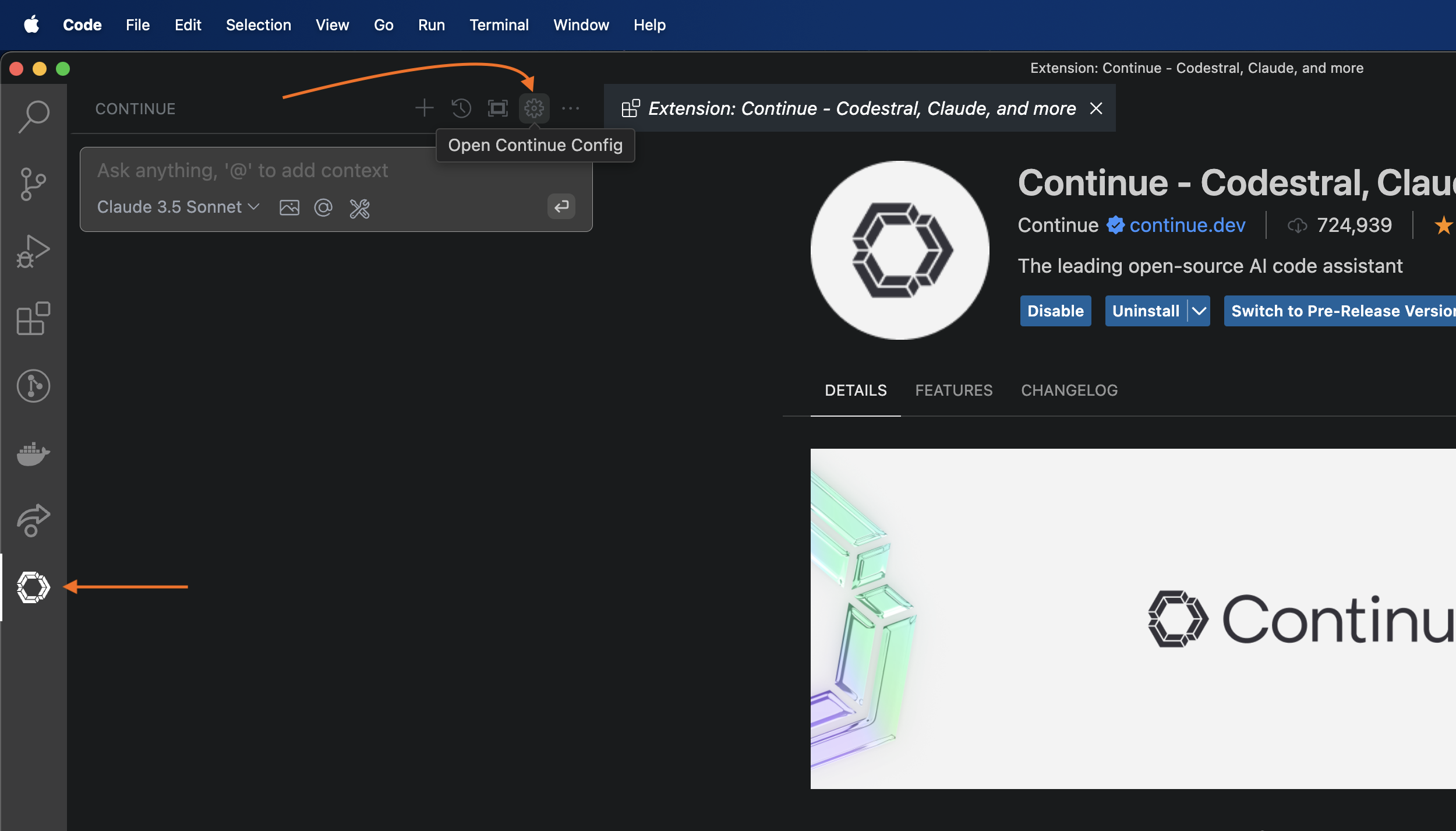
Now we need to configure Continue extension to use ollama's Qwen2.5 Coder LLM model which we have running already from previous section. Click on Continue icon on the activity bar (left most side panel) & then click on Open Continue Config button (gear icon) as shown in below image.
It will open a config.json file, here we need to specify model name, title and provider in two blocks models & tabAutocompleteModel like below:
...
"models": [
{
"title": "Qwen 2.5 Coder 7b",
"model": "qwen2.5-coder:7b",
"provider": "ollama"
}
],
"tabAutocompleteModel": {
"title": "Auto Complete",
"model": "qwen2.5-coder:7b",
"provider": "ollama",
"apiKey": ""
},
...After this changes config.json should look like this:
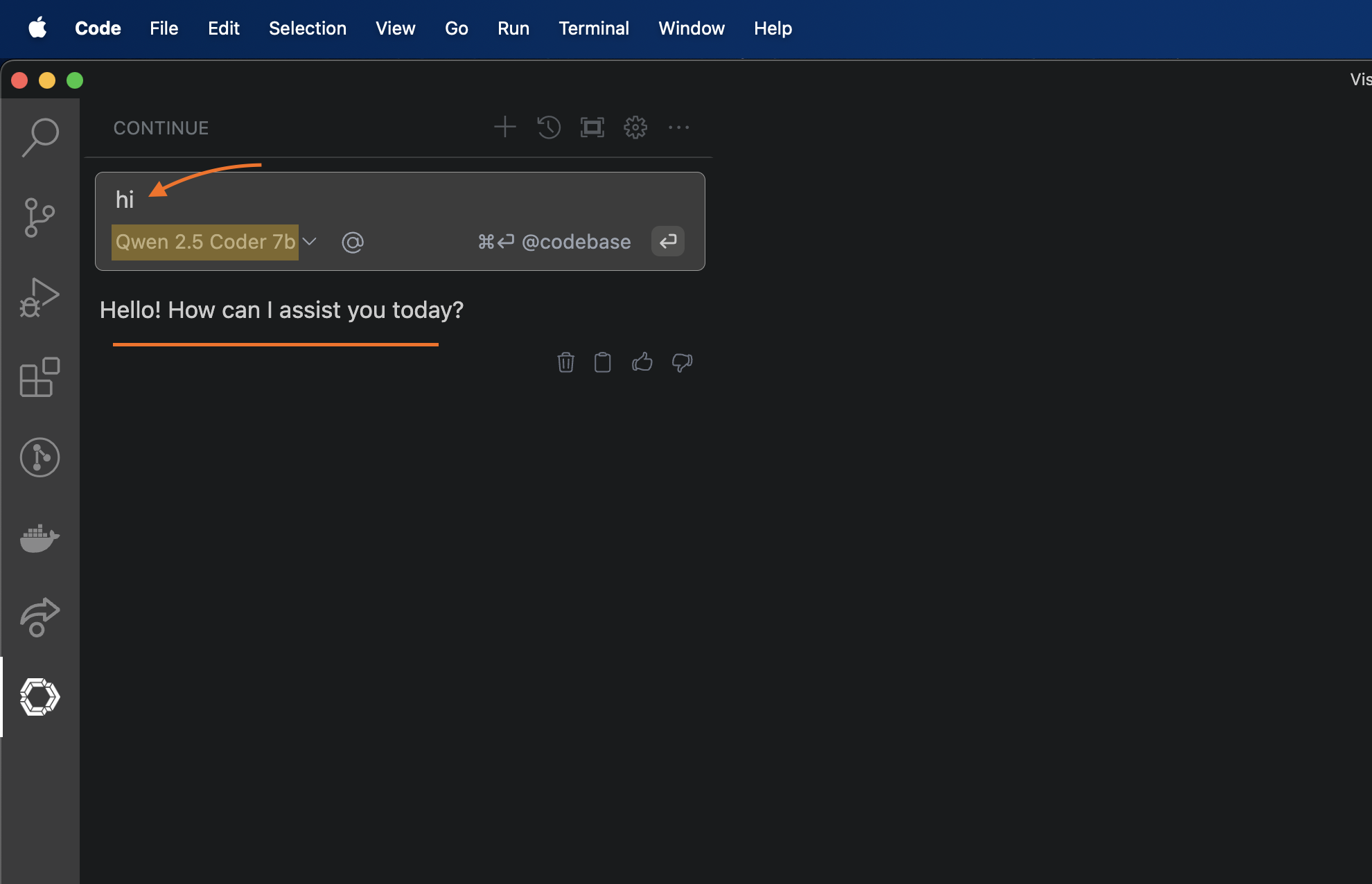
Save the config file and close it, now in the continue chat side panel, you should see Qwen 2.5 Coder 7b selected & you can type hi & hit enter key.
You now have a working ChatGPT like AI chatbot inside VS Code that can run offline & most importantly your chats & data stays in your computer!!
Code Completions
After completing previous section, we can now test the code completions in VS Code. I have created an empty folder and opened it in VS Code. I then create a new javascript file code app.js and written some code comments for Continue to generate code:
When code suggestions appear, press Tab key to accept it.
I hope this was helpful, see you next time!
A Small Request From Your Fellow Developer 💙
What took you 10-15 minutes to read took me several days to perfect. And honestly? That's completely worth it when I know it saves you hours of frustration.
🫤 Here's the reality: Creating quality tech content takes countless late nights testing different setups, breaking my own system multiple times, taking screenshots at every step, and then rewriting everything until it makes perfect sense. If this helped you, please consider supporting my work! 🥳
{ "Small support": "Big motivation to create more content!" }